Ce premier volet de notre série se concentrera principalement sur la définition de la “DATA”, terme un peu nébuleux pour nombre d’entre nous 🤔. Nous aborderons ensuite de manière un peu plus détaillée l’utilisation de la donnée dans le monde informatique, avec quelques exemples adaptés au secteur agricole. Pour cela nous traiterons de 4 grands thèmes 📊📊 :

“Les données informatiques sont des informations traitées ou stockées par un ordinateur, qui peuvent prendre la forme de documents textes, images, clips audio, logiciels ou d’autres types de données.” (TechLib)
Elles permettent ainsi de représenter le monde qui nous entoure en décrivant ses diverses composantes. Il faut dans un premier temps identifier les éléments qu’il sera intéressant de stocker pour le bon fonctionnement des outils développés. Par exemple, pour pouvoir faire un suivi cultural, il faut pouvoir caractériser son agrosystème. En résumé il est composé d’une parcelle, sur laquelle est implantée une culture, qui a des caractéristiques botaniques et sur laquelle on va amener des intrants. Les données dans cet exemple sont donc :
Il s’agit ensuite de relier ces données entre elles et d’essayer de comprendre la nature de leurs interactions. A cette étape nous sommes amenés à nous poser une question importante pour la suite : de quelle manière peut-on représenter ces données ?
“En informatique, un modèle de données est un modèle qui décrit la manière dont sont représentées les données dans une organisation métier, un système d'information ou une base de données.” (Wikipédia)
Autrement dit, c’est la manière dont les données influent les unes sur les autres et la manière de représenter ces interactions. Par exemple, prenons une personne : Jack JOHNSON, qui porte une paire de chaussures.
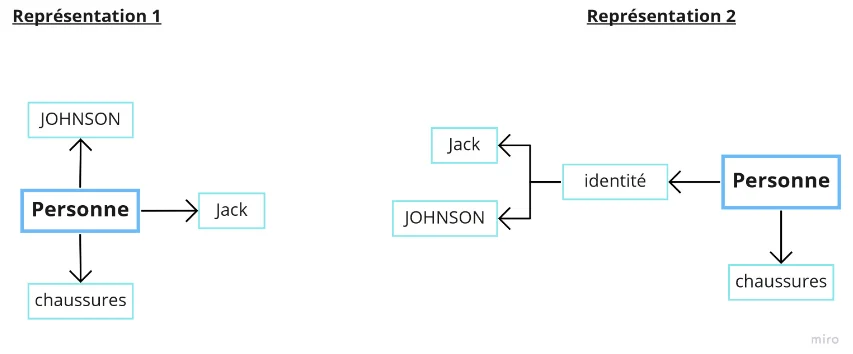
Voici deux manières de représenter ces informations (fig. ?). La Représentation 1 de ces données ne dispose pas de logique particulière ou d’organisation précise de l’information. La personne est simplement associée à des « objets », sans description de cette association ni des éventuels liens entre ces objets. La Représentation 2 par contre décrit mieux la situation : la personne porte d’une part une identité composée du nom et du prénom ; et d’autre part des chaussures.
Eh bien il se passe la même chose pour décrire le monde agricole :
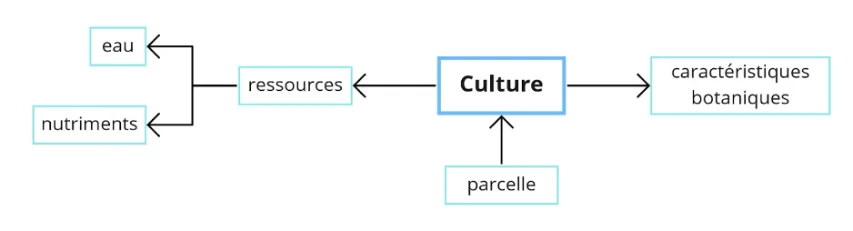
On retrouve les données mentionnées précédemment, mais cette fois-ci elles sont organisées entre elles et communiquent les unes avec les autres : la culture porte des caractéristiques botaniques, reçoit des ressources (eau, nutriments) et est implantée sur une parcelle.
Il existe une grande diversité de représentation des données, dont le modèle relationnel communément utilisé. Il se base sur un schéma concret et statique, où les données sont organisées sous forme de tables formées de lignes et de colonnes (voir fig. ?).
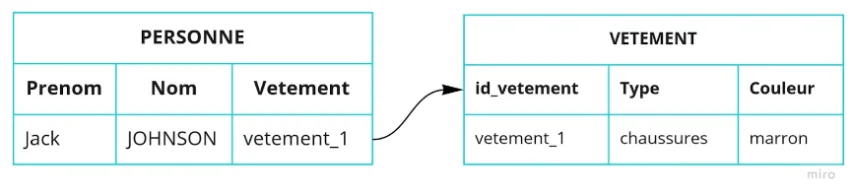
De par son architecture, cette modélisation est relativement limitée lorsqu’il faut gérer un grand nombre de données connectées. Lorsqu’il s’agit de modifier l’architecture de la base, cela demande également une réorganisation importante des données, ce qui rend cette représentation moins flexible qu’une modélisation en base graphe.
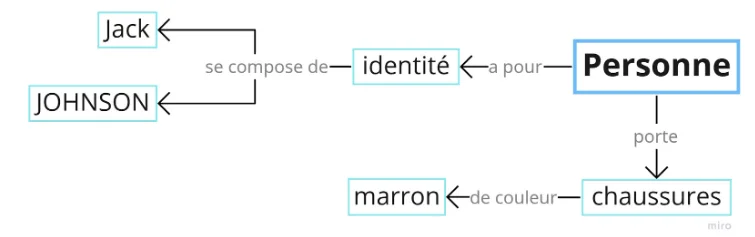
Cette dernière fonctionne sur une base de nœuds reliés entre eux par des arcs (voir fig. ?) et non pas en tables de données. Chaque nœud représente une donnée qui est liée à un autre nœud par une relation, chacun des nœuds et arcs peut porter des propriétés. Ce modèle permet une grande interconnexion des données, une facilité dans leur traitement ainsi qu’une grande flexibilité dans l’évolution du modèle. On comprend donc pourquoi, dans le cas où l’on veut représenter un domaine très complexe comme peut l’être le domaine agricole, l’utilisation d’une base graphe est moins contraignante, moins limitante.
Pour faciliter la manipulation de l’outil par l’utilisateur, il convient parfois de pré-renseigner une partie des données. En agriculture, c’est en effet un des enjeux principaux que d’alléger la saisie de données afin de rendre l’utilisation des outils informatiques par les professionnels la plus simple et la moins chronophage possible. De nombreux projets ont ainsi eu pour but de générer des informations faisant référence dans un domaine et faites pour être réutilisées : ce sont les référentiels.
Des organismes développent des listes de données utilisables, qui décrivent un sujet précis. Les référentiels constituent un ensemble structuré d’informations, pouvant être des références d’un système d’information, utilisé pour l’exécution d’un logiciel. Définir un référentiel clair, logique et précis permet une bonne interopérabilité d’un système d’information, en créant un cadre commun à plusieurs applications (Wiktionnary, Wikipédia).
Dans l’agriculture, ces référentiels peuvent concerner : la liste des familles botaniques, les espèces et variétés des cultures principalement utilisées en France, la liste des agrofournitures présentes dans la filière maraîchère, ou encore la liste des produits phytosanitaires avec leurs caractéristiques.
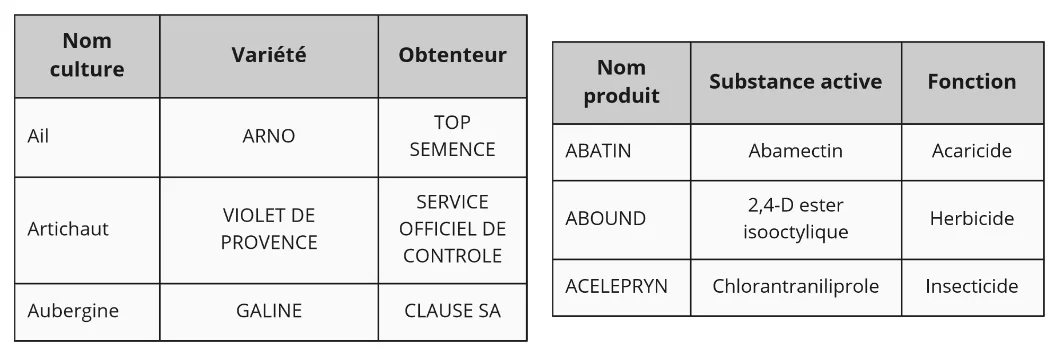
Sur ces socles communs de la connaissance peuvent venir se brancher, plusieurs applications. C’est un des principaux intérêt des référentiels. En effet, ils présentent des données solides sur lesquelles un consensus a été trouvé. Cela permet à différents outils de parler de la même notion et donc de pouvoir communiquer les uns avec les autres.
Par exemple, si un outil renseigne des données de rendements moyens de tomate sur une zone géographique donnée, et qu’un autre outil branché au même référentiel géographique renseigne les données météorologiques pour cette même zone, il sera aisé de lier les données climatiques aux rendements de tomate mesurés.
Cette interopérabilité, ainsi que la fidélité de représentation de notre environnement, peuvent être améliorées grâce à des technologies comme le web sémantique.
Le Web Sémantique est une extension du Web où les connaissances doivent être structurées et accessibles sur Internet pour être exploitée automatiquement par les machines. En effet, les données provenant des pages web sont souvent inutilisables par les machines car elles sont stockées sous forme de texte sans réelle structure.
Imaginée par le créateur du Web, Sir Tim Berners-lee, cette idée est basée sur les technologies dites de graphes où les connaissances sont des “objets” ou “points” et les liens qui les unissent sont des relations qui décrivent une connaissance. En structurant les données de cette façon et en appliquant la théorie des graphes, nous pouvons appliquer des algorithmes et requêtes sur ces graphes pour apporter de nouvelles connaissances.
Les données sont représentées sous la forme de triplet, c’est-à-dire que l’on a une source, une destination et une relation (le lien) entre ces deux points. Par exemple, une Courgette est_de_la_famille_botanique cucurbitacées. L’image ci-dessous représente 3 triplets ayant pour source de départ Courgette.
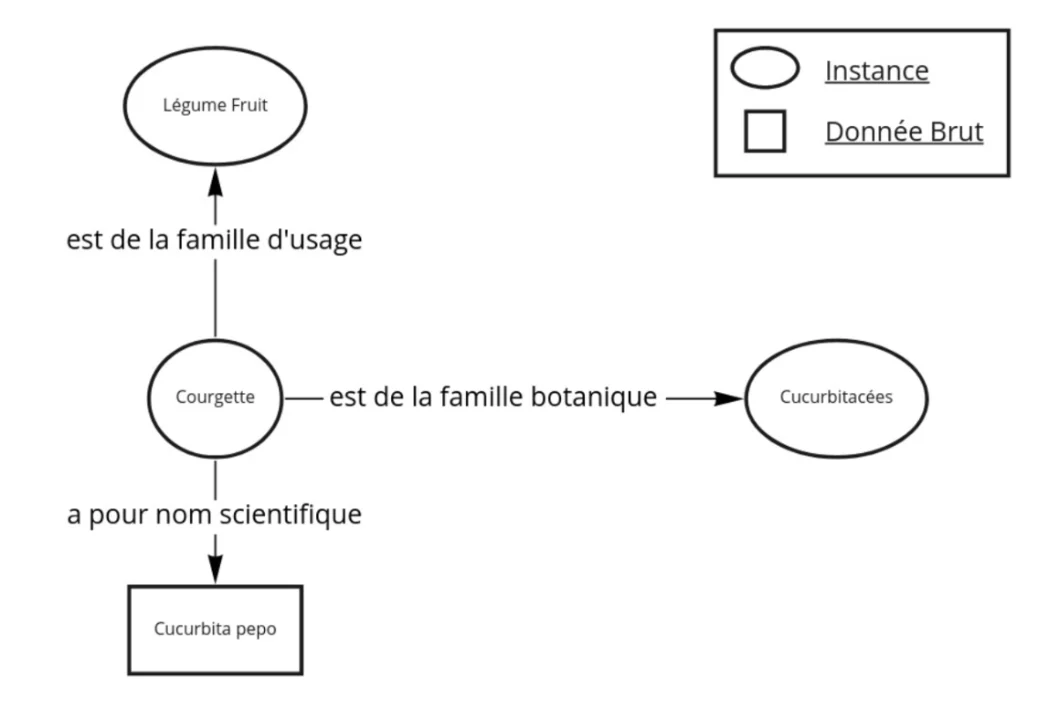
Si dans l’exemple les données sont des mots, dans le monde du Web Sémantique, les données sont majoritairement représentées par des URI. Une URI, pour Uniform Resource Identifier, est un lien sur le web qui porte l’information en question et permet de décrire ou d’atteindre facilement le reste des informations qui lui sont rattachées.
Ressemblant aux adresses URL classiques que vous avez sur votre navigateur et qui vous emmène sur vos pages web préférées, les URI ont pour vocation a être un lien vers une information directement référencée dans une base de données.
Voici L’URI de la courgette dans DbPedia, l’équivalent Wikipedia pour le domaine du web sémantique : http://dbpedia.org/resource/Zucchini
En cliquant sur ce lien, vous arriverez directement sur la page de la courgette et vous aurez accès à l’ensemble des informations enregistrées sur la courgette.
Dans un triplet, les sources et les liens des triplets sont toujours représentés par des URI alors que la destination peut être une autre URI ou bien une donnée brute comme une phrase, un nombre, une date, etc. Cette URI peut permettre de continuer la navigation dans le graphe.
Le graphe de connaissances se constitue en attachant des triplets ensemble. L’organisation du savoir est formalisé dans un modèle de données et est utilisable par les machines pour communiquer de l’information. Un autre intérêt à construire des graphes de connaissances est de pouvoir prédire des nouvelles relations entre les données, soit en intégrant des règles sémantiques dans les graphes, soit en utilisant des méthodes d’intelligence artificielle.
Si vous en tant qu’humain vous avez cliqué sur lien vers la page “courgette” de DBPedia, dites vous que les machines communiquent grâce à des langages spéciaux qui permettent d’atteindre les données plus facilement.
Il existe des langages pour utiliser ou interroger ces informations et graphes de connaissances. Ce sont des recommandations publiques officielles du Word Wide Web Consortium. L’intérêt du Web Sémantique est de pouvoir développer une connaissance partagée, ouverte et standardisée, facile d’accès et réutilisable.
L’objectif, à terme avec le Web Sémantique, est qu’un maximum de données soient connectées entre elles pour avoir un savoir qui communique et qui se nourrit d’un effort commun, nous parlerons alors d’interconnexion des données. L’image ci-dessous nous montre des graphes de données (les points) et les connexions qui existent entre elles, produisant au final une grande toile de connaissances accessible et utilisable par tous.
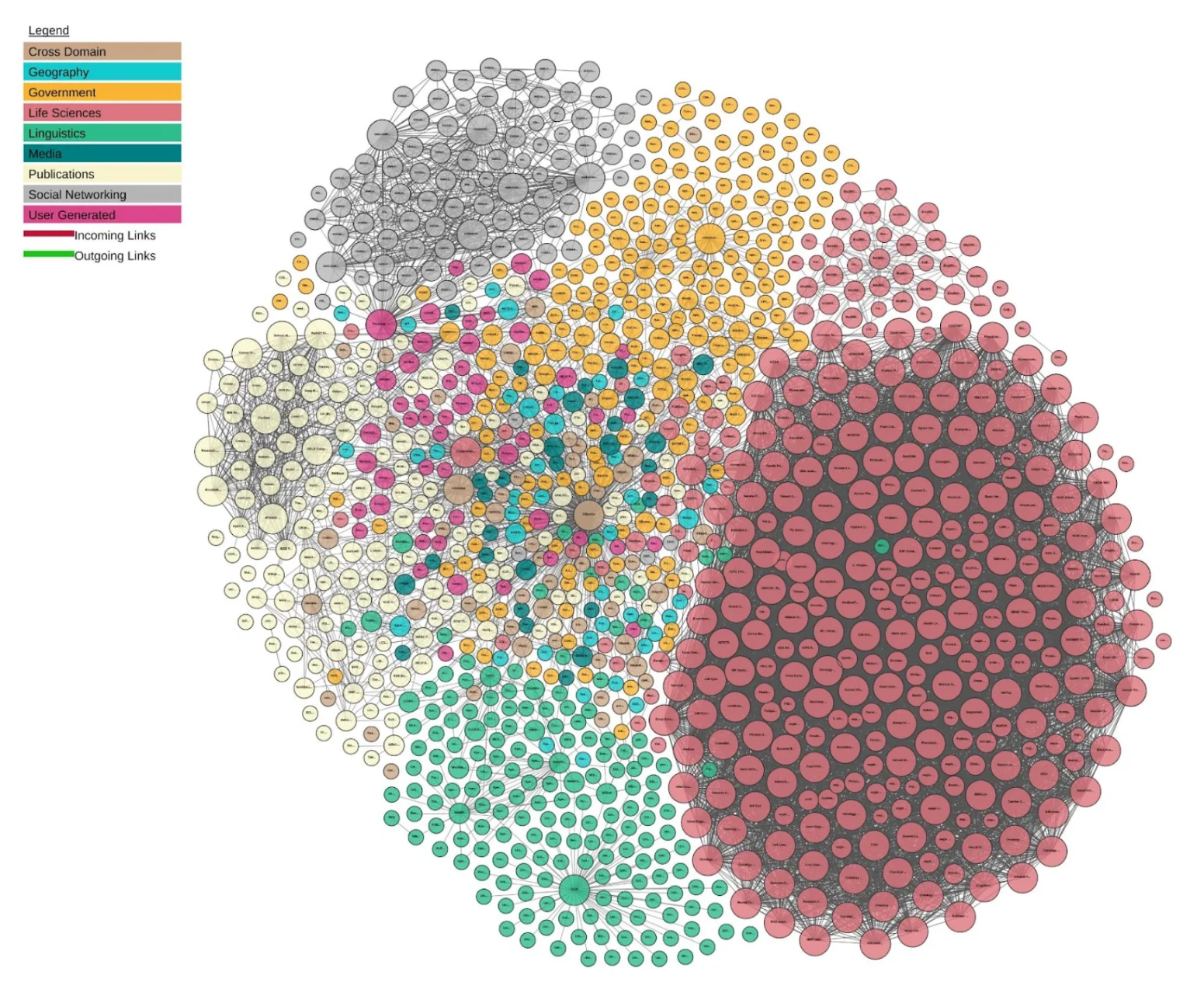
Pour décrire cette connaissance et organiser les données en son sein, sous forme de TRIPLETS, il convient de définir le modèle. Pour cela, il est commun de construire une ontologie.
Une ontologie, c’est un modèle de données qui a pour vocation de représenter une partie du savoir. Il existe une multitude d’ontologies différentes : La représentation du monde animal et végétal, de la musique, de la nourriture, des pièces de voitures, des types de sports etc. Et même du maraîchage ;).
L’objectif d’une ontologie est de structurer les données. Elle est composée de classes et de propriétés entre classes ou des types de données, ce qui permet de structurer la connaissance. Les données sont contrôlées en saisie par le modèle pour alimenter la base graphe. Grâce à ces ontologies, les utilisateurs peuvent plus facilement participer à l’amélioration de la connaissance car ils suivent un format préétabli.
Chaque ontologie a pour vocation de représenter une partie de la connaissance qui lui est propre, elles ont toutes une sémantique particulière. Les utilisateurs peuvent plus facilement communiquer entre les différents modèles de données et les différentes bases car ils comprennent plus facilement comment les données sont organisées.
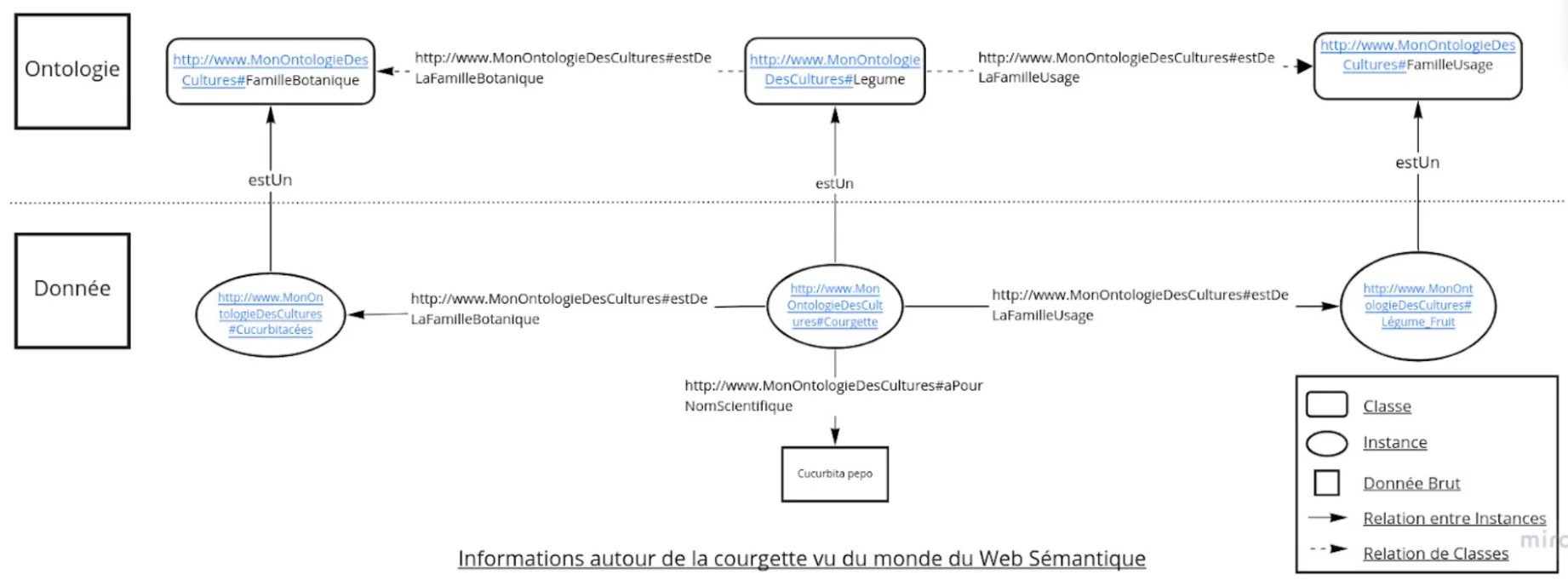
En reprenant notre exemple des légumes, nous pouvons construire un début d’ontologie.
Un exemple de modèle serait :
Classes: Plante (Courgette), Famille d’usage (Légumes), Famille Botanique (Cucurbitacées).
Relations: estUn
Nous retrouverons les relations vues précédemment qui seraient répétées entre les classes. Grâce à ce modèle, nous avons notre MODELE et les données seront construites en suivant ce format.
Pour défricher notre compagnon numérique et aller plus loin, prenez rendez-vous avec Gilles, l’un de nos associés, pour une présentation personnalisée de l’application !